Data streaming, unlike integration paradigms based on batch streams or APIs that focus mainly on the state of the business entities being handled, focuses on the collection, management and exchange of events between applications and systems.
An event describes a change that has occurred, at a specific moment in time, in the state of an entity of interest. Since it is always possible to reconstruct the state of an entity from change events, streaming systems allow the state of applications to be transferred asynchronously and in a highly scalable manner between the systems concerned.
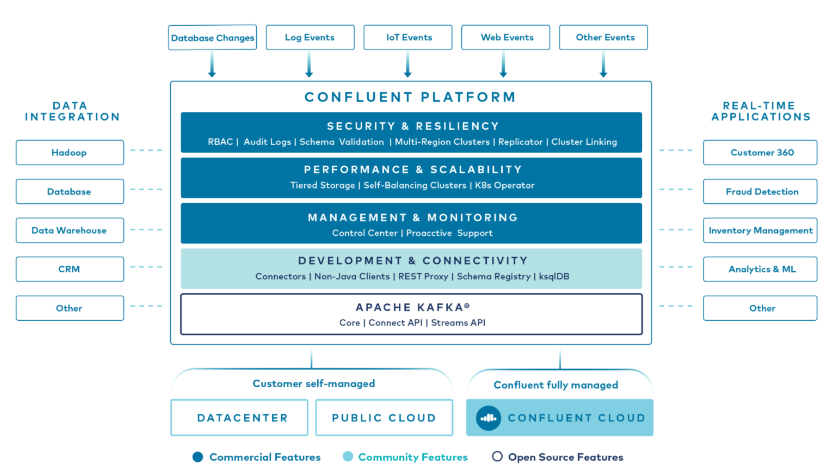
Kafka is one of the world’s most widely used platforms for managing streaming data and real time data integration. The Confluent platform, whose company was founded by the creators of Kafka, expands its benefits with enterprise-level functionality by reducing TCO and facilitating management and usage.
We consider it essential to evaluate the real-time component from the outset in the realisation of new use cases, since subsets and snapshots of data can always be derived from it for different types of consumption, whether real-time or batch. On the other hand, a flow of data managed in batch mode cannot produce a continuous flow of data as an output. This type of flow is preferred because there is usually a perception that realising real-time flows is more complex than managing batches of data, ignoring the fact that their future evolution (which may be required following a change in requirements) typically requires greater effort and cost than an additional initial effort to process data streams.
The greater speed of integration provided by stream-based architectures provides an important competitive advantage in terms of user satisfaction and the effectiveness of actions taken in response to what happens. Our conception of streaming platforms does not only envisage their feeding from operational data sources for consumption by operational and analytical systems, which is the standard use case, but is also open to the collection of information from analytical systems (e.g. collecting the output of a machine learning model) and its propagation to operational systems.
Consider, for example, how important it is in an omnichannel scenario to be able to align physical shop and e-commerce in real time, or to provide personalised recommendations to the customer while he or she is still in the shop or on the site and not the next day, or to detect fraud at the same time as banking transactions and not afterwards.