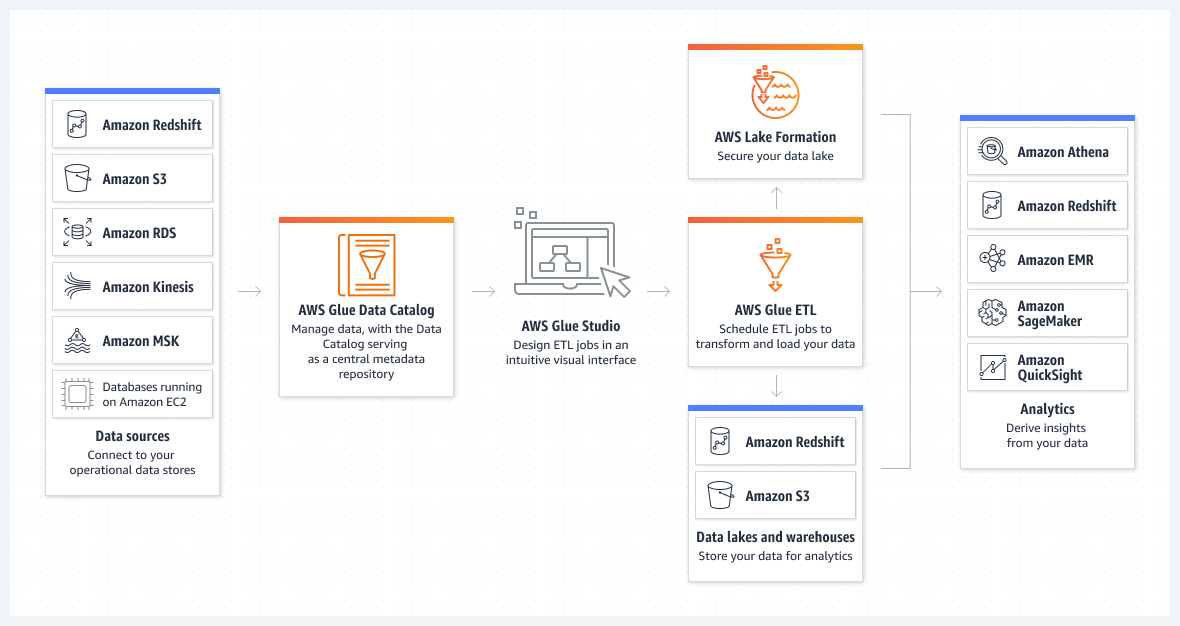
AWS Glue consolidates the main data integration functionalities into a single serverless service. Key functionalities include:
- Data Classification
Function that uses crawlers to determine the technical schema of data. AWS Glue provides classifiers for the most common file types, e.g. CSV, JSON, XML, AVRO. It also provides classifiers for the most common relational database management systems using a JDBC connection.
- Data Catalog
Persistent metadata repository: the catalogue contains table definitions, process definitions and other control information for managing data entities in AWS.
- ETL/ELT
AWS Glue Jobs system provides a managed infrastructure for defining, planning and executing ETL/ELT operations on data in order to prepare and consolidate the data and enable its analysis.
- Streaming Processing
In addition to batch modes, it is possible to create streaming processing operations that are executed continuously, e.g. consuming data from Apache Kafka, Amazon Kinesis Data Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK).