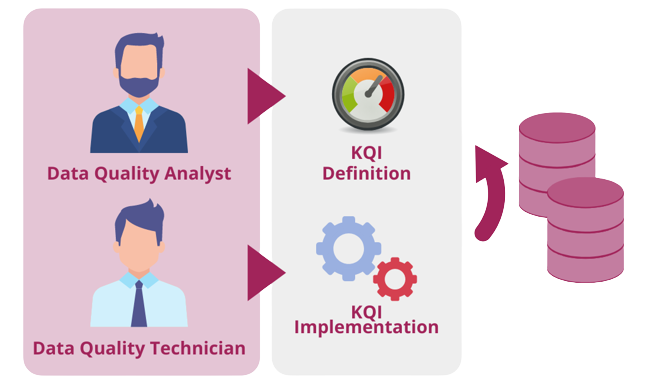
The success of companies is increasingly linked to an intensive use of data. The ‘data driven’, if not ‘algorithm driven’ approach seems to be winning. However, its success is closely linked to the availability of good quality data, where quality is defined as fitness for purpose. In particular, the DMbok identifies 6 dimensions of quality: Completeness, Uniqueness, Timeliness, Validity, Accuracy, Consistency, each of which must be analyzed and declined in relation to the context and needs of each individual company.
The continuous monitoring of ‘key’ data used in the definition of corporate strategies is a first point to ensure correct decisions. In the dynamic contexts that have characterized the market in recent years, being able to count on quality data is the key to reacting to change in a timely manner, exploiting the opportunities provided by new technologies and making them functional to achieving success.