L’uso quotidiano dei motori di ricerca su dati aziendali (di clienti, di prodotto, di procedure interne…) è ormai diffuso in maniera capillare, sia da parte degli utenti di business che da parte dei clienti. L’utilizzo così diffuso di questa tecnologia ha generato crescenti aspettative sulla ricerca hanno portato a importanti progressi, come la ricerca semantica, che vanno oltre le capacità di ricerca per parole chiave. Tuttavia, sia la ricerca per parole chiave che quella semantica hanno importanti compromessi da considerare:
- Considerare solamente le parole chiave in una ricerca può implicare una perdita di parti importanti del contesto
- Considerare solamente la ricerca semantica può implicare una perdita di parole chiavi importanti
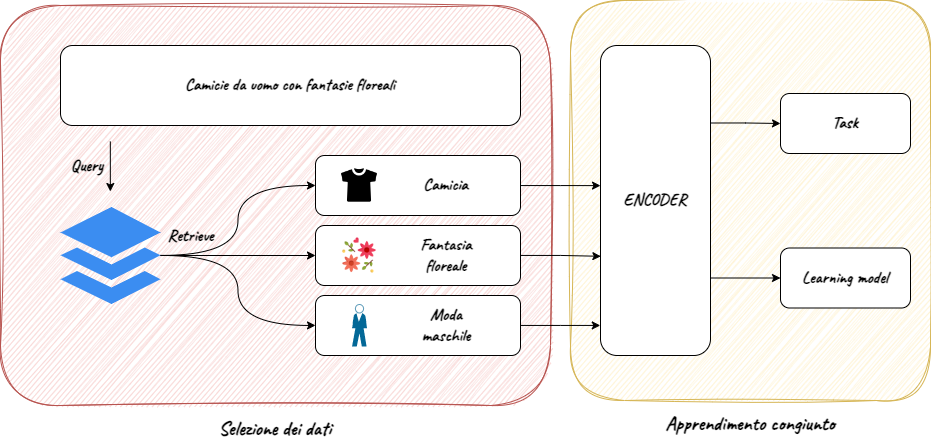
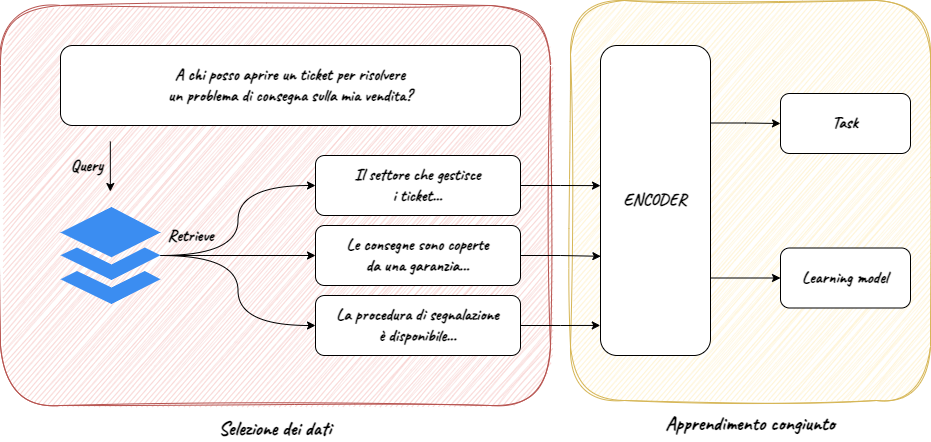
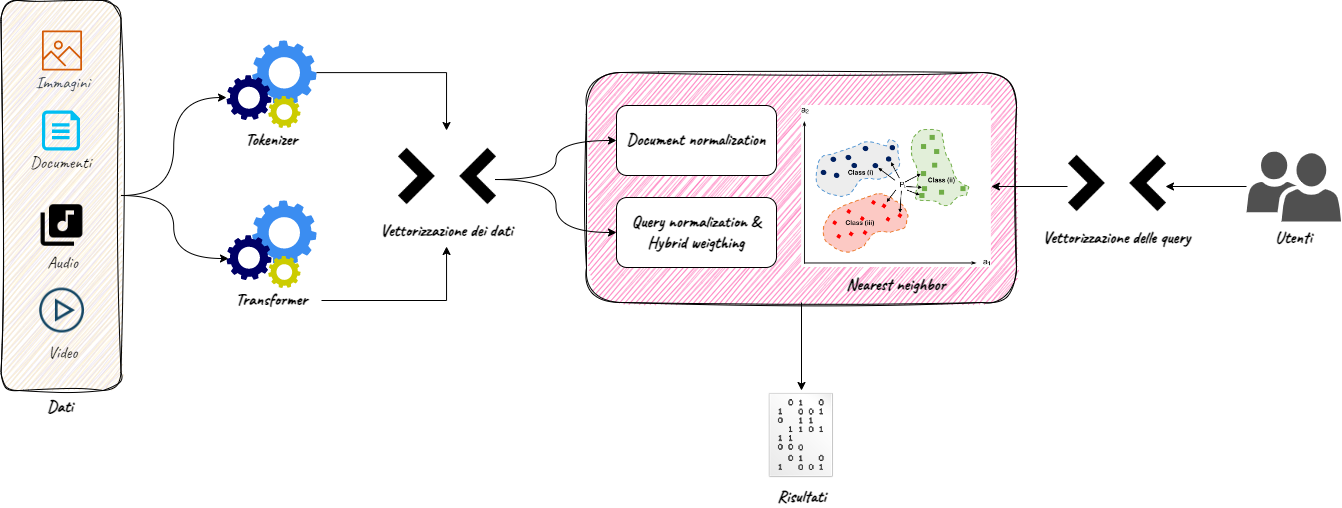
Inoltre, sempre più spesso è necessario cercare o restituire informazioni su dati destrutturati come immagini o video, specie per quanto riguarda la ricerca su siti ecommerce o in ambito di ricerca documentale.
La Multimodal Semantic Search rappresenta un nuovo approccio alla ricerca delle informazioni, pensata espressamente per gestire contemporaneamente parole chiavi, contesto semantico e scraping di dati strutturati e destrutturati, per offrire un’esperienza di ricerca personalizzata, puntuale e completa.