Through our advisory services, we guide our clients in defining their data strategy and implementing solutions with a modern approach to data management. It is within this process that we also evaluate the suitability of the data mesh paradigm both organizationally and technologically. To support the implementation of data mesh, we have also produced tools to manage technology and governance-related challenges.
Our solution starts with understanding an organization’s reality and its needs, which is achieved during the analysis phase of defining the data strategy. This phase clarifies all functional and application elements of an organization, including difficulties and expectations, business model and organizational structure, processes and domains, systems and data. This is followed by the solution definition, which is aligned with the same dimensions. If applicable, the adoption of the data mesh paradigm and the details for its implementation are evaluated.
If the context is deemed suitable for the adoption of the data mesh paradigm, two ingredients are essential to enable the development of its basic components, the data products:
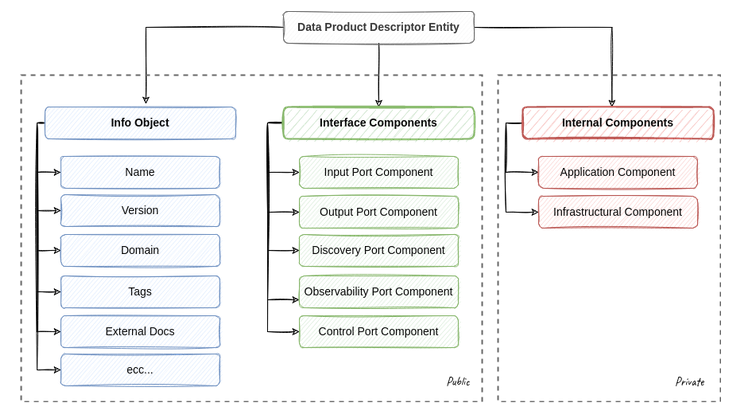
→ a contract that formally describes external interfaces, internal components, and who is responsible for the exposed data
→ a platform capable of maintaining these contracts, enforcing them, and using them to automate the product lifecycle in self-service mode
The contract is critical as it ensures a shared and clear method for describing all elements of the data products. The platform’s role is to make data product management as simple, scalable, and automated as possible by using its internal services and workflows, such as registration, validation, creation, and distribution.
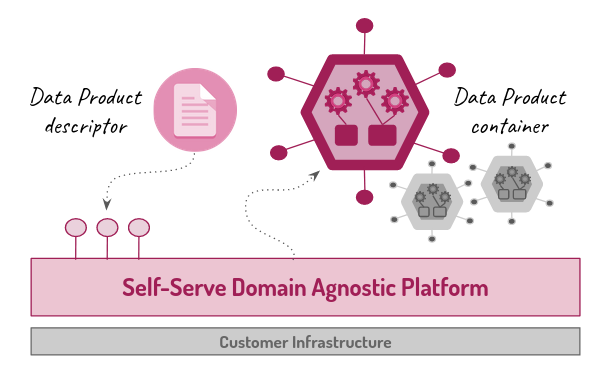
The specification, and consequently the descriptor, describes the data product, while the platform uses the descriptors to automate the product’s operations. We adopt the Data Product Descriptor Specification (DPDS) as the specification, an open specification that declaratively defines a data product in all its components using a JSON or YAML descriptor document. It is released under the Apache 2.0 license and managed by the Open Data Mesh Initiative. DPDS is technology-independent and collects the description of all the components used to build a data product, from infrastructure to interfaces. DPDS is designed to be easily extendable using custom properties or leveraging external standards such as OpenAPI, AsyncAPI, Open SLO, etc., to define its components.
Using the specification, it is possible to guarantee interoperability among various data products by centrally defining policies, the responsibility of the federated governance team, while product teams are responsible for implementing products that conform to these standards.
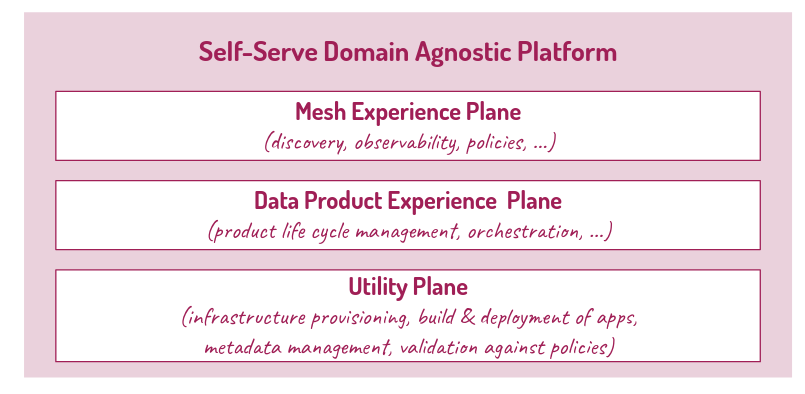
For implementation, reliance is placed on a platform shared among various product teams and accessible in self-service mode. The architecture’s goal is to control and facilitate the implementation of shared standards, contain the cognitive load on various product teams, reduce TCO, and automate data management activities as much as possible. Its services can be organized into these three groups:
→ Utility plane: Responsible for providing services for accessing underlying infrastructure resources. The exposed services decouple consumers from the actual resources provided by the underlying infrastructure
→ Data product experience plane: Offers a series of operations for managing the data lifecycle: creation, updating, version control, validation, distribution, search, and deactivation
→ Data mesh experience plane: Capable of operating with multiple data products by leveraging their metadata, aims to offer a marketplace where data products can be searched, explored, and connected
The Open Data Mesh (ODM) platform is the solution we use internally to implement this architecture. It will be open source in early 2023. Currently, the ODM platform only covers the services of the utility plane and the data product experience plane, while the data mesh experience plane can be developed using governance tools available on the market, such as Collibra or Blindata, or through custom solutions.
The Utility Plane exposes the main functionalities of the underlying infrastructure, which will later be orchestrated by the data product experience plane to provide high-level services to product teams in a self-service and declarative way. Some examples of services commonly exposed by the utility plane include:
→ Policy Service, which controls global governance policies
→ Meta Service, which propagates metadata associated with data products to a dedicated metadata management system such as Confluent Schema Registry, Collibra or Blindata.
→ Provision Service, responsible for managing the infrastructure
→ Build Service, which compiles applications and generates executable artifacts
→ Integration service, which deploys application artifacts
The Utility Plane decouples the services of the Data Product Experience Plane from the underlying infrastructure, allowing for independent evolution with minimal impact on already implemented products. Each service of the Utility Plane is composed of a standard interface and a pluggable adapter that interacts with a specific underlying infrastructure application, making the platform easily extendable and adaptable.
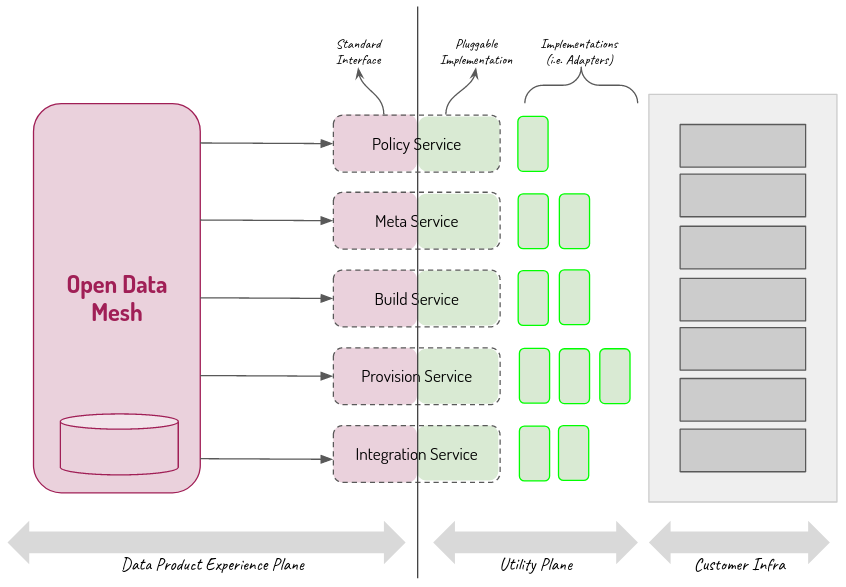
The Data Product Experience Plane exposes the necessary services to manage the lifecycle of a data product. Among the basic services that a typical product plane must provide are the Registry Service and the Deployment Service. The Registry Service allows you to publish and associate a new version of the descriptor with the data product and make it available on demand. The Deployment Service is responsible for managing, creating, and releasing the Data Product Container based on the descriptor. To do this, it orchestrates the services offered by the Utility Plane in the following way:
- Analyzes the application code and generates an executable file, where necessary, using the Build Service.
- Creates the infrastructure using the Provision Service.
- Registers all metadata in the external metadata repository through the Meta Service.
- Distributes the applications using the Integration Service.
Additionally, every time there is a significant change in the state of the data product, it is possible to call the Policy Service to check compliance with global criteria.