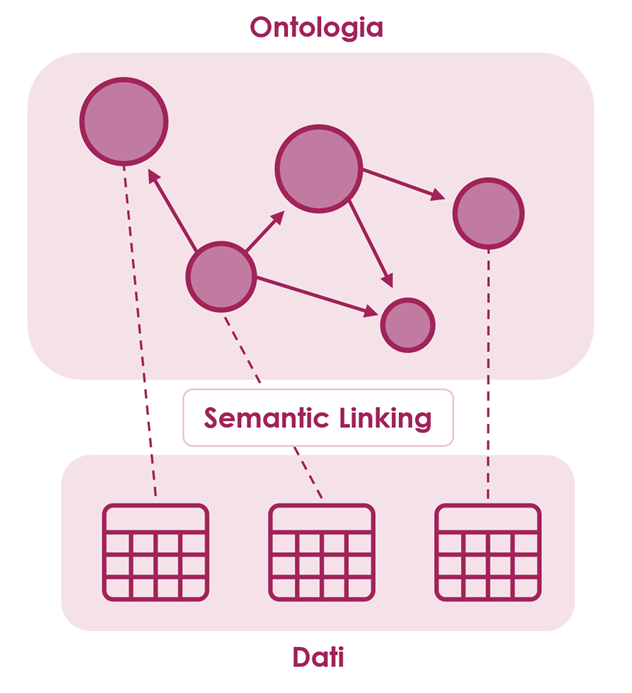
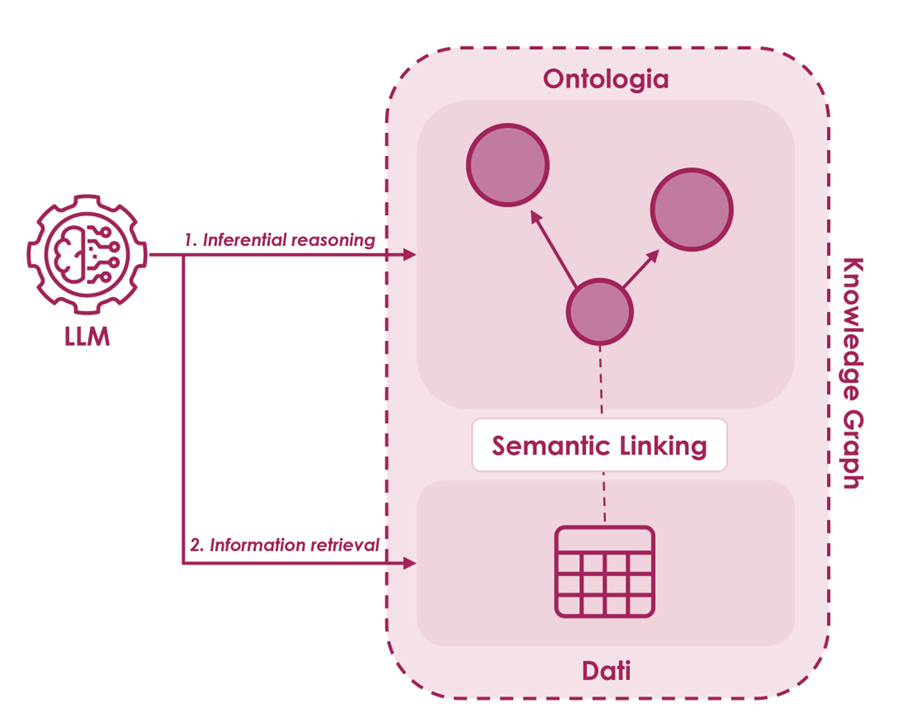
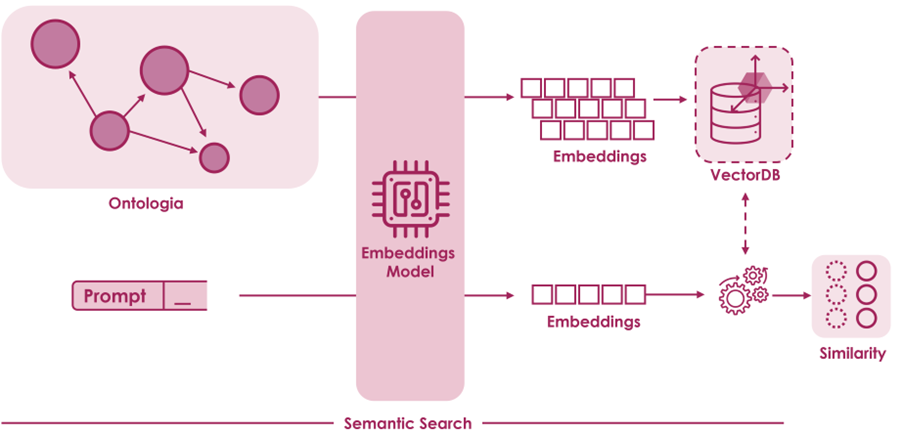
In an increasingly complex and interconnected digital information network, organizations can benefit from the acquisition and integration of new data of interest to their business.
The heterogeneity of sources and formats, combined with the high amount of resources, risks making the implementation of a process onerous which, albeit with some simplification, is often banal at its base but must deal with the continuous evolution of its driver.
In fact, it is not uncommon to see the use of manual operations to derive value from unstructured information, with the aim of finding the most immediate solution to a problem in the absence of adequate technological support. This approach, however, requires high time and costs, as well as exposing us to the risk of valorization errors due to the often alienating nature of the collection tasks.
To date, there are several software solutions capable of extracting information from unstructured sources, enabling the automation of the process through a predefined series of steps. These solutions often require high and continuous tuning efforts and are typically static approaches. This is the case of solutions capable of recognizing the occurrence of a specific pattern (e.g. the VAT number of a company) in a predefined position (e.g. on the header of an invoice at the top right) but which lose effectiveness if the data is indicated in a different position or with a different label, albeit semantically similar (e.g. using synonyms, abbreviations: VAT number or VAT code, etc.). Clearly these situations can also be handled by extending existing algorithms to incorporate known variations, but it is impossible to handle all possible ones with this approach.
Thanks to the support of AI it is now possible to quickly implement more flexible and effective solutions.