The Fourth Industrial Revolution is strongly characterized by the desire to make the most of digital technology not only to optimize business processes but especially to enable new data-driven services for the company. In this new era of digitization, the IT ecosystem is based on the centrality of data, considered first-class company assets that can be reused for multiple use cases, both operational and analytical.
To maximize the extractable value from data offers several factors of competitive advantage, such as enhancing services provided to the end customer, ensuring new insights, making predictions about future business trends using advanced artificial intelligence-based analysis techniques, improving integration between traditional software systems and new digital applications (web and mobile), generating new revenue opportunities through data sharing and monetization.
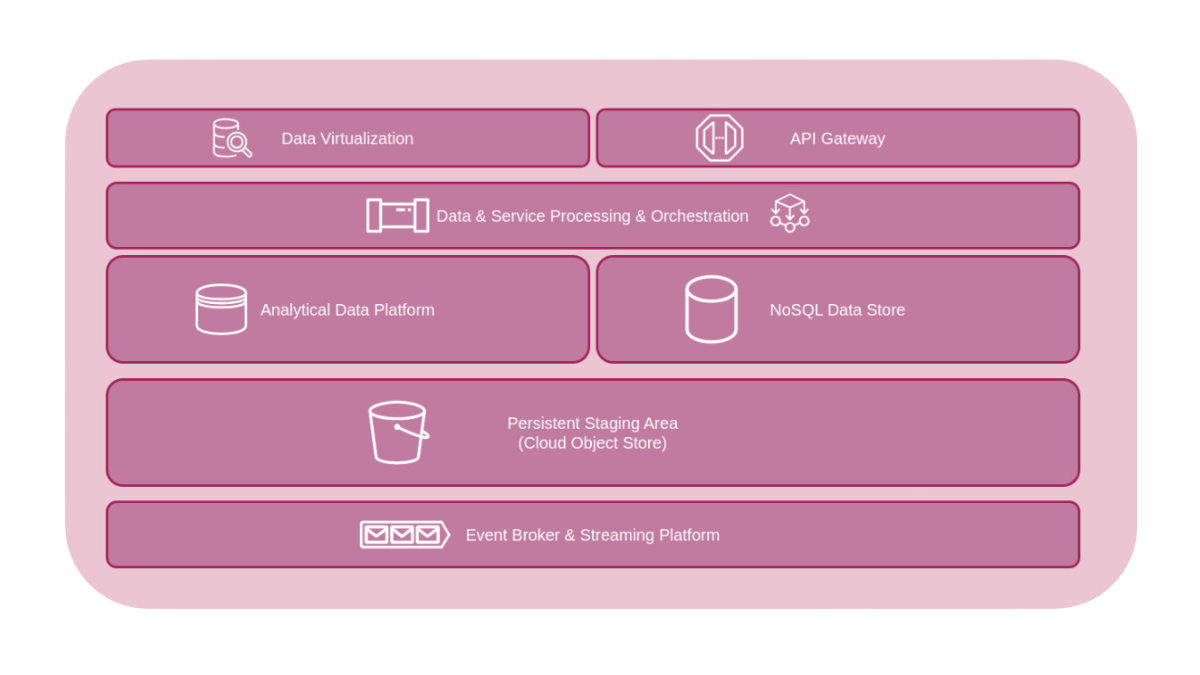
To achieve these objectives, it is necessary to have an integration platform that facilitates access, sharing, and use of data by applications different from those that generated the data itself. Such a scenario represents a turning point compared to the past when IT architectures were designed with an approach that gave more centrality to investment in domain applications (Systems Of Record), to the detriment of data management. The integration of the latter was considered a secondary aspect, to be addressed purely functionally to enable individual use cases as they arose, without a real forward-looking data management strategy. Applications were designed in a way that was not oriented toward sharing but toward storing data internally: this aspect made data reuse as an asset difficult and limited the extractable value from it.
The data-centric movement is strongly contributing to changing the thinking paradigm, and this has led to the emergence of new architectural patterns that are more in line with data sharing and reuse principles than platforms based on point-to-point ETL integrations or traditional SOA architectures. Among these, the Digital Integration Hub pattern is particularly interesting for its ability to make domain data available to different consumers in a scalable and efficient manner by making the best use of modern cloud-based technologies.