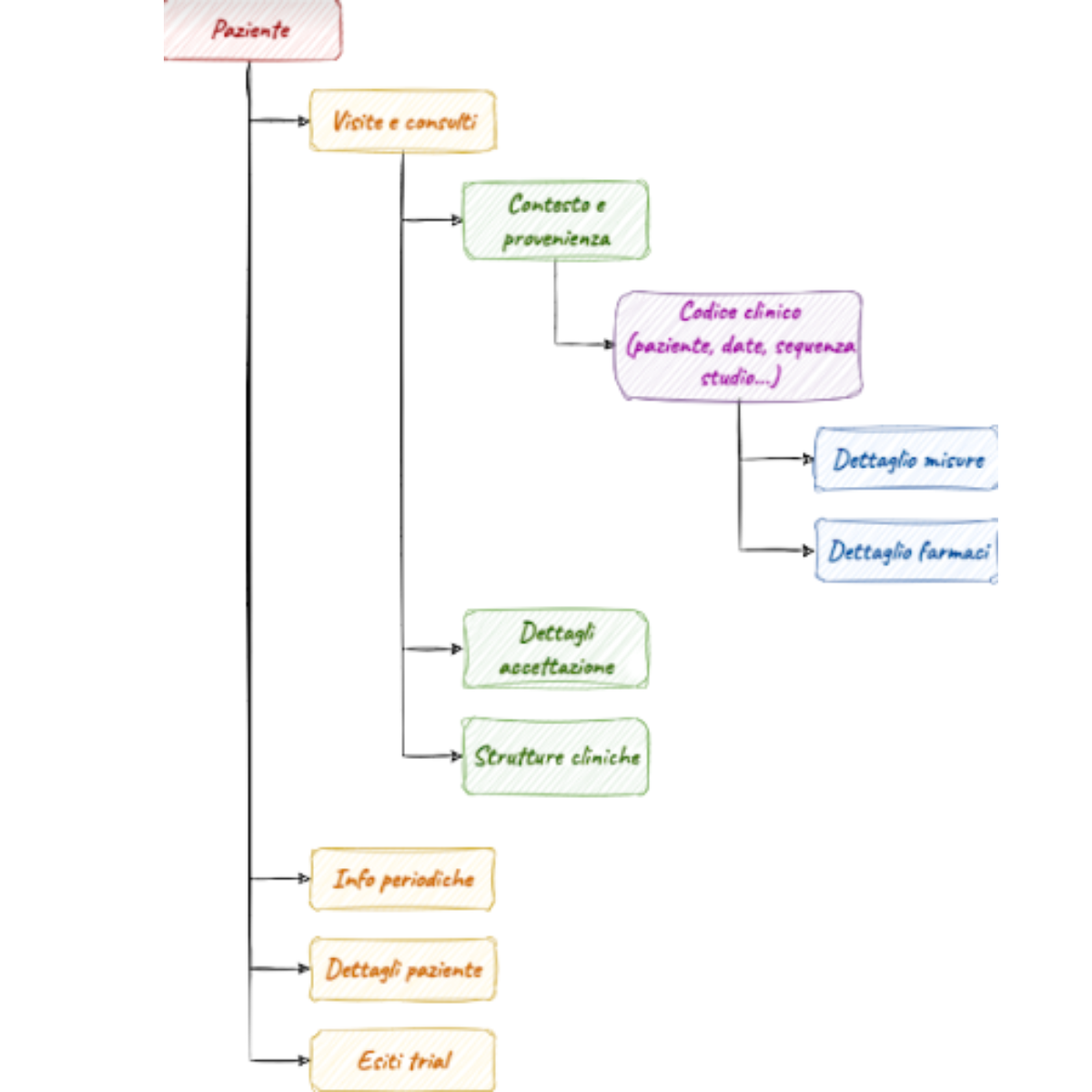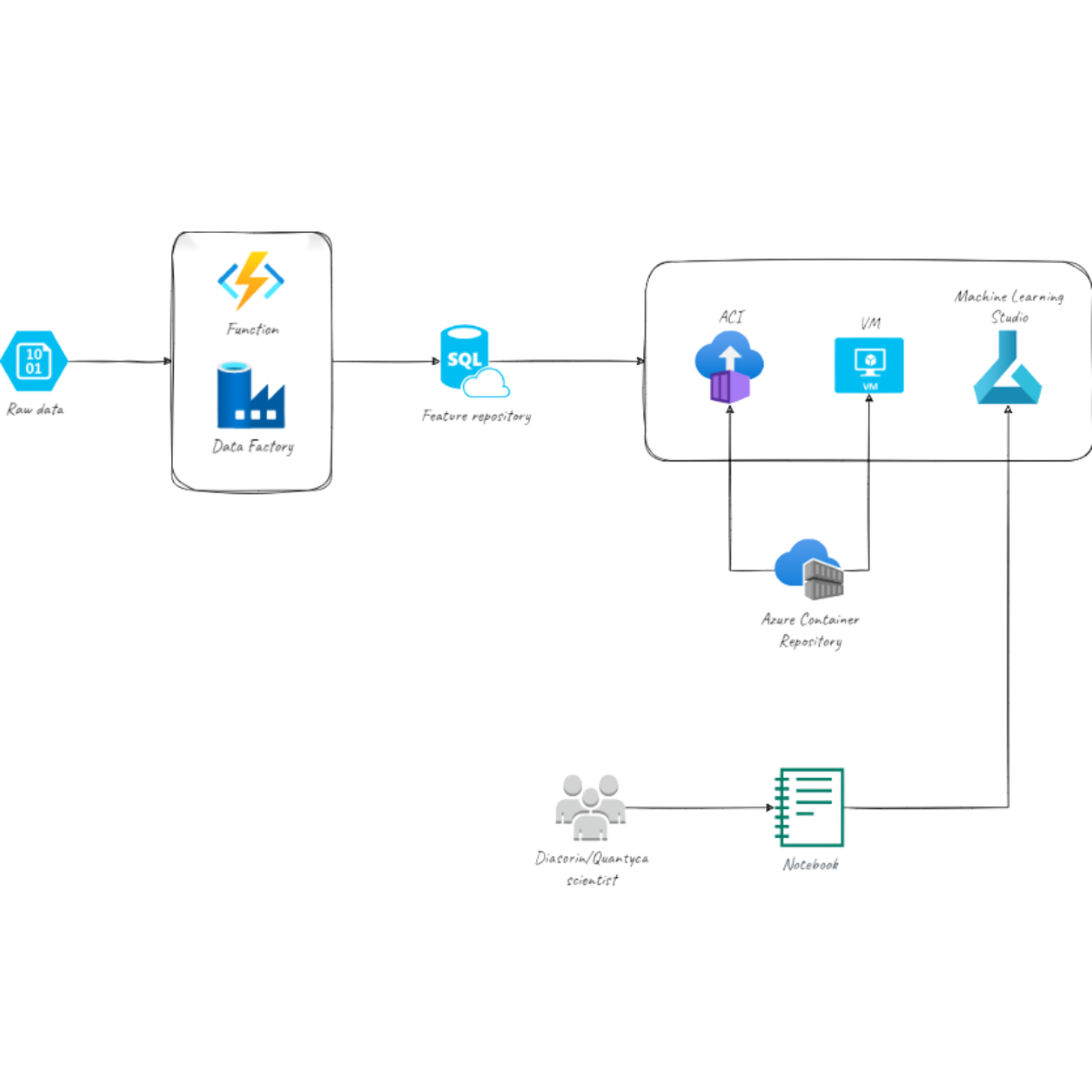
For more than 50 years, Diasorin has been developing, manufacturing and marketing laboratory diagnostic reagent kits worldwide through 45 companies, 4 divisions, 10 production sites and 9 research and development centres. This organisation enables Diasorin to have a broad offering of diagnostic tests and licensed technology solutions, made available through continuous investment in research.
The variety of the offer and investment in research and innovation qualify Diasorin in its market as the player with the widest range of specialised solutions in the sector and identifies the Group as the ‘Diagnostics Specialist’.