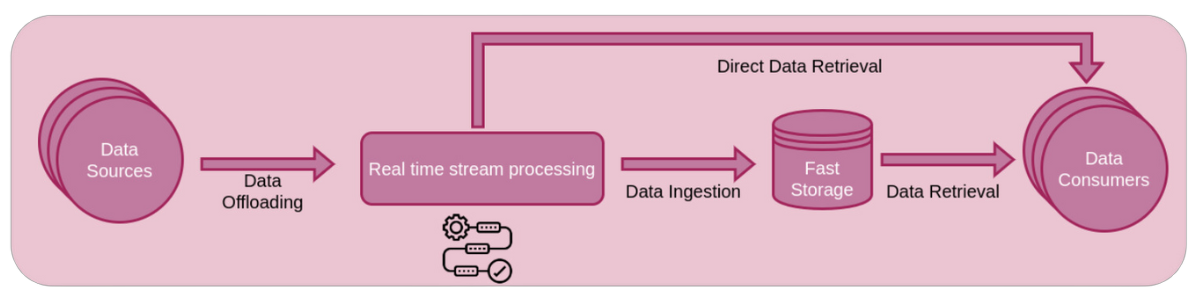
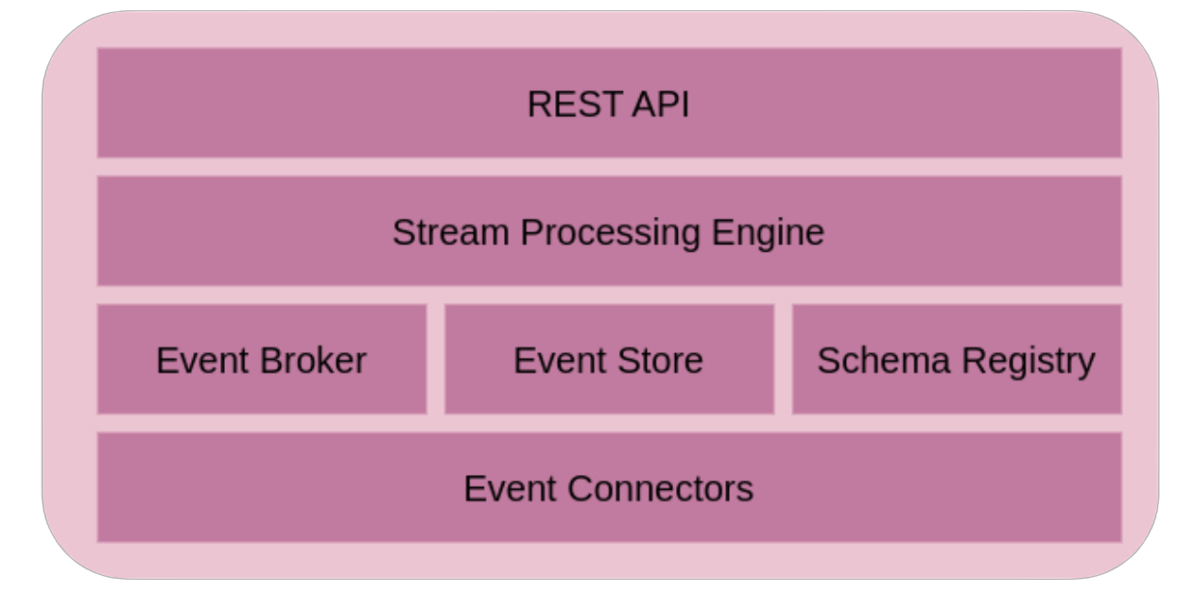
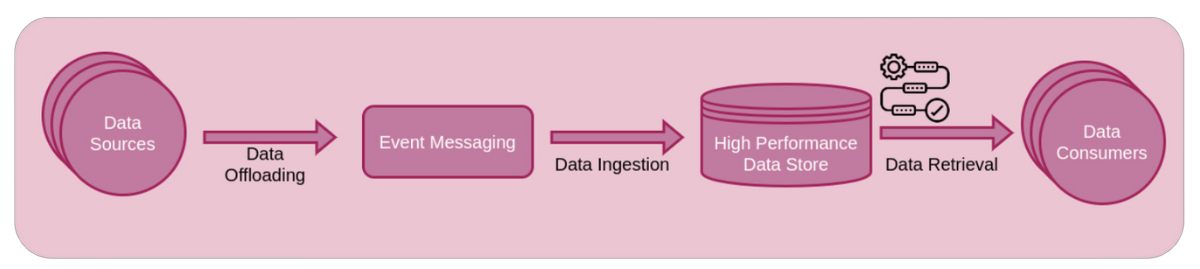
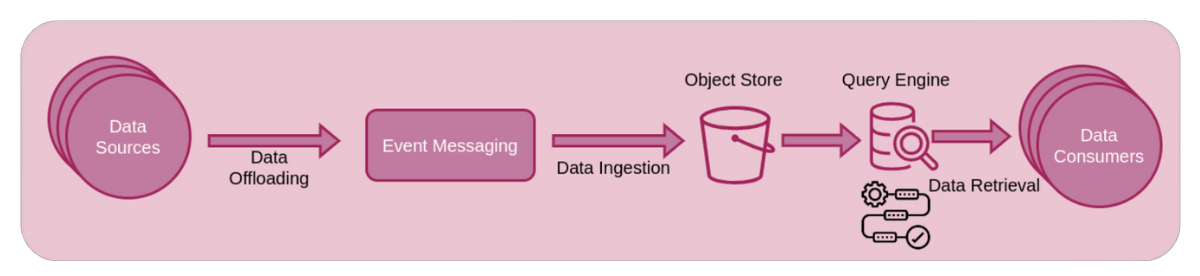
In diversi settori aziendali la velocità dei processi di decision-making è sempre più cruciale per il profitto dell’organizzazione: sfruttando un monitoraggio continuo della performance del core business basato su un’analisi dei dati in tempo reale, il management può prendere tempestivamente delle decisioni per massimizzare le entrate dai vari canali e mitigare le perdite dovute a iniziative errate o fattori esterni.
Per le aziende digital native l’analisi in real time di fenomeni come il comportamento dei clienti nell’interazione con i touch point permette di migliorare in tempi rapidi l’efficacia di suggerimenti automatici all’utente, aumentando l’engagement e migliorando l’esperienza con i servizi offerti. Al contrario, la mancanza di tempestività dell’adattare o correggere un’iniziativa digitale verso il cliente finale può portare ad una perdita di appetibilità e di fiducia nel servizio con conseguenti perdite in termini di potenziali ricavi o sospensione delle sottoscrizioni.
La possibilità di avere visibilità in tempo reale sull’andamento del business può essere un abilitatore di vantaggio competitivo anche per le aziende dei settori più tradizionali, come il retail, che possono avviare iniziative di marketing o campagne promozionali con molta più rapidità rispetto al passato, specialmente nei periodi dell’anno di saldi o eventi straordinari.
Inoltre, la capacità di elaborare gli eventi di dominio in tempo reale è spesso un requisito necessario per supportare l’operatività del business stesso, come nel caso delle funzionalità di prevenzione di frode per gli istituti bancari sulle attività di on-banking o di calcolo in tempo reale dell’inventario per le aziende retail multicanale.