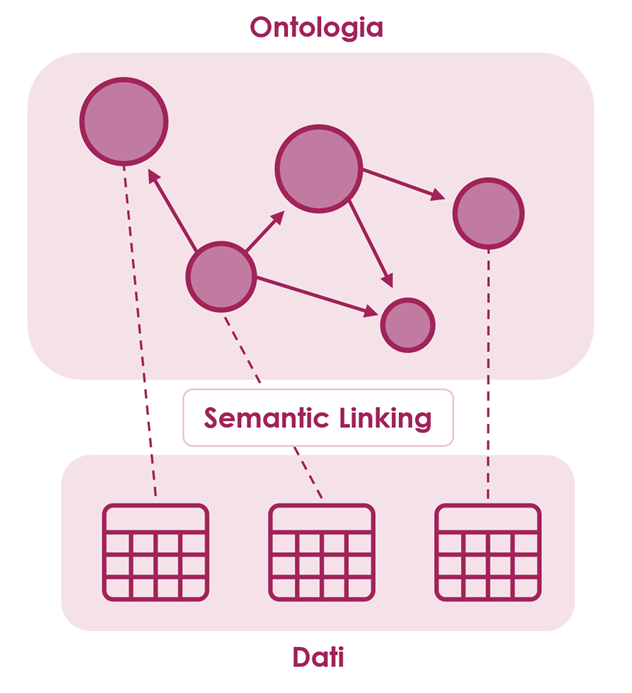
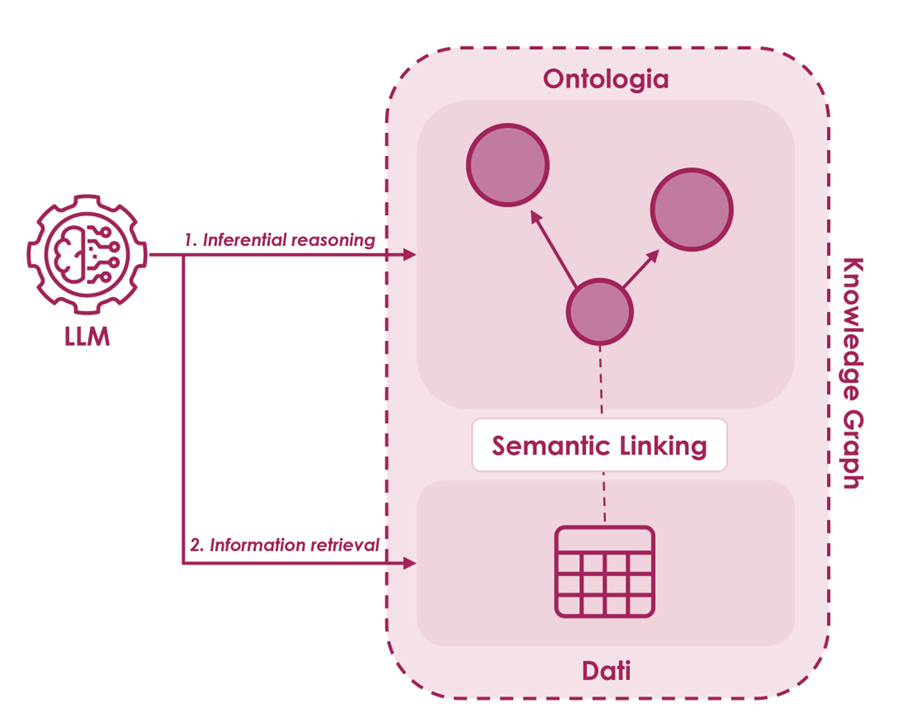
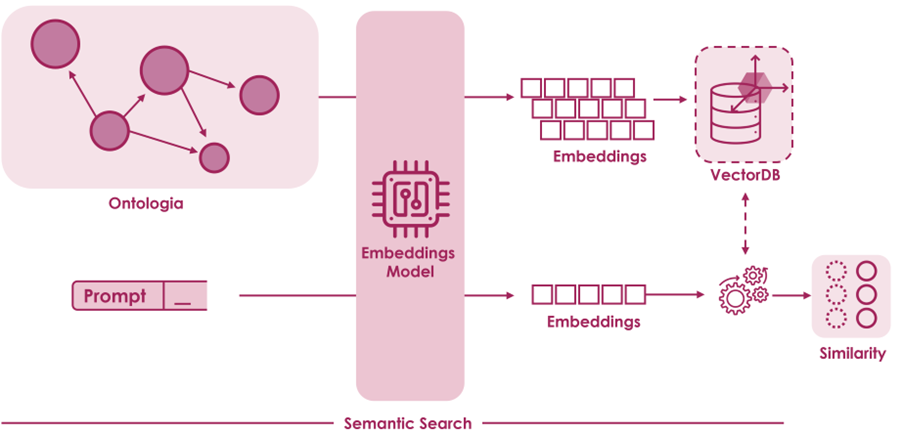
In una sempre più complessa e interconnessa rete di informazioni digitali, le organizzazioni possono trarre vantaggio dall’applicazione di processi di Document Intellgence per acquisire ed integrare nuovi dati di interesse per il proprio business.
L’eterogeneità delle fonti e dei formati, unita all’elevata mole di risorse, rischia di rendere onerosa l’attuazione di un processo che, seppur con qualche semplificazione, alla base è spesso banale ma deve fare i conti con la continua evoluzione dei propri driver.
Non è infatti raro assistere all’impiego di operazioni manuali per ricavare valore da informazioni non strutturate, allo scopo di trovare la soluzione più immediata ad un problema in assenza di un adeguato supporto tecnologico. Questo approccio, tuttavia, richiede tempi e costi elevati, oltre ad esporre al rischio di errori di valorizzazione per la natura spesso alienante dei task di raccolta.
Ad oggi esistono svariate soluzioni software in grado di estrarre informazioni da fonti non strutturate, abilitando l’automazione del processo attraverso una serie predefinita di steps. Queste soluzioni richiedono spesso elevati e continui effort di fine-tuning e sono tipicamente approcci statici. E’ il caso di soluzioni in grado di riconoscere l’occorrenza di un pattern specifico (es. la partita iva di una società) in una posizione predefinita (e.g. sull’intestazione di una fattura in alto a destra) ma che perdono efficacia se il dato viene indicato in una posizione diversa o con una label differente, seppur semanticamente analoga (es. usando sinonimi, abbreviazioni: P.iva o vat code, ecc). Chiaramente anche queste situazioni possono essere gestite estendendo gli algoritmi esistenti per incorporare le variazioni note, ma è impensabile gestire tutte quelle possibili con questo approccio.
Grazie al supporto dell’AI è ora possibile implementare rapidamente soluzioni più flessibili ed efficaci per l’estrazione di valore da dati non strutturati.