Il mercato dei dati e degli analytics continua a crescere costantemente e tutte le organizzazioni riconoscono nei dati un asset chiave per il proprio vantaggio competitivo. Tuttavia il data management si trova in difficoltà tra il dover soddisfare le richieste continue e il dover fare i conti con team IT che fanno da collo di bottiglia e i cui principali sforzi sono legati alla gestione dei dati e alle integrazioni necessarie per la loro fruizione.
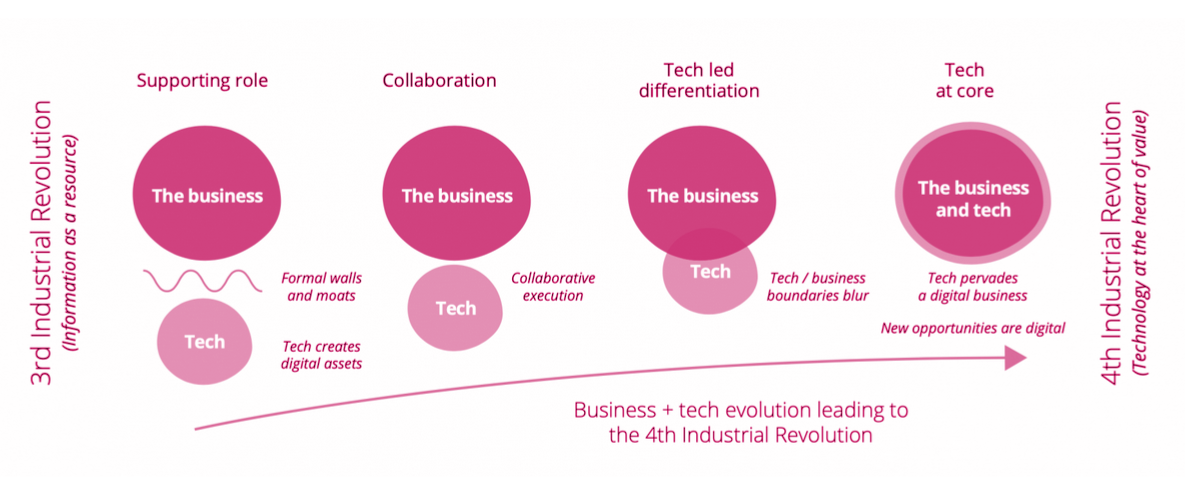
Storicamente l’IT veniva visto come un centro di costo alla mercé del business e la tecnologia come uno strumento per creare asset digitali, nel tempo c’è stata una convergenza che, con la quarta rivoluzione industriale, ha visto il riconoscimento del ruolo centrale della tecnologia non solo per digitalizzare i processi ma anche per la realizzazione di nuovi processi o modelli di business.
L’IT ha sempre meno una funzione di supporto e si afferma come vera e propria funzione di business. I dati sono protagonisti di questo cambio di assetto, spodestando il ruolo ricoperto storicamente dalle applicazioni, e imponendo un ripensamento e adeguamento del data management.
Tra le principali difficoltà degli approcci tradizionali al data management ci sono:
- l’inadeguatezza del budget IT, che non cresce in modo proporzionale alla domanda e porta ad un gap tra richieste del business e capacità di delivery dell’IT
- l’esigenza della digital transformation di un numero costantemente in crescita di applicazioni
- la crescita dell’offerta tecnologica e la spinta della digital transformation, che portano ad un aumento della spesa per le integrazioni
- la sempre maggior complessità delle integrazioni, dovuta principalmente a :
- approccio storicamente centrato sulle applicazioni
- moltiplicarsi delle sorgenti e dei consumatori dei dati
- convergenza tra use case transazionali e analitici
I moderni approcci al data management al fine di poter scalare i processi di acquisizione, consolidamento e utilizzo dei dati si concentrano su aspetti di natura sia organizzativa che tecnologica. A livello organizzativo il focus è sulla scalabilità del modello operativo, realizzata per mezzo di:
- gestione strategica dei dati come prodotti
- decentralizzazione delle ownership sui domini
A livello tecnologico il focus è sull’automazione dei processi di integrazione, realizzata per mezzo di:
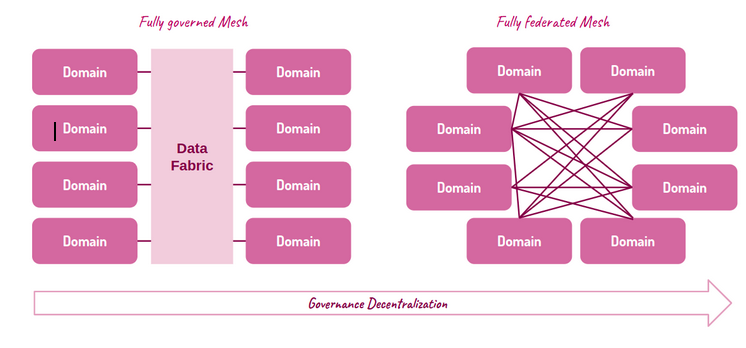
Mentre l’approccio Data Fabric si sofferma esclusivamente sugli aspetti tecnologici, il Data Mesh si concentra prima sugli aspetti organizzativi per poi arrivare a quelli tecnologici e si fonda su quattro principi:
→ Domain Ownership
distribuire le responsabilità relative ai dati non per fase della pipeline di integrazione (ad esempio, ingestion, transformation, enrichment, ecc.) ma per dominio di business (ad esempio, Product Discovery, Payments, Shipment, ecc..). La responsabilità del dato è più prossima al team che lo produce e non è affidata ad altri intermediari.
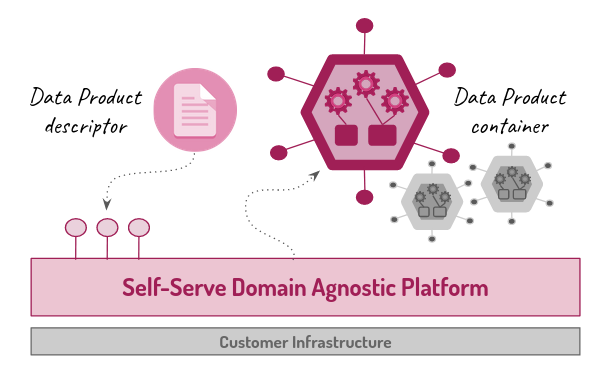
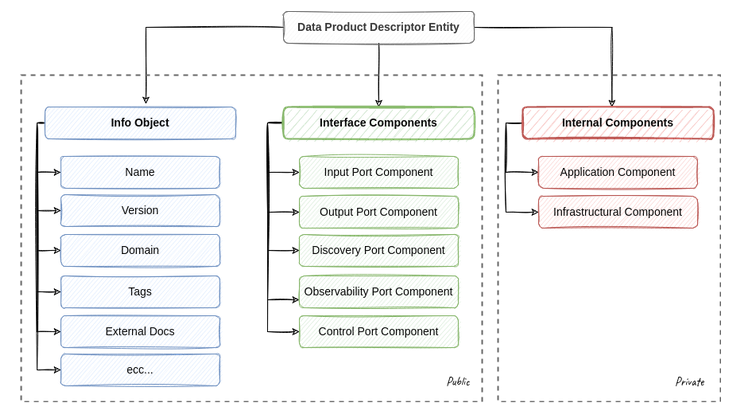
→ Data as a Product
trattare come un vero e proprio prodotto, ad esempio definendo in modo chiaro le loro interfacce di accesso, garantendone la qualità, prevedendone il versionamento, documentando tutto il necessario e rispettando SLO e SLA concordati con i diversi consumatori. Un prerequisito è la possibilità di gestire il dato insieme ai processi che lo generano e all’infrastruttura sottostante come un unità atomica di deployment (architectural quantum).
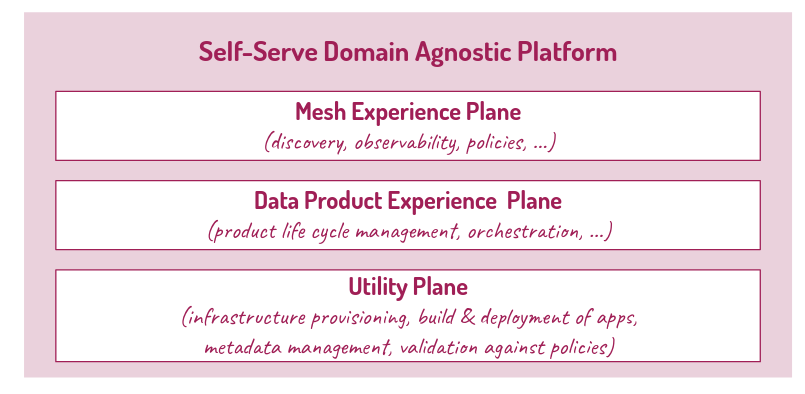
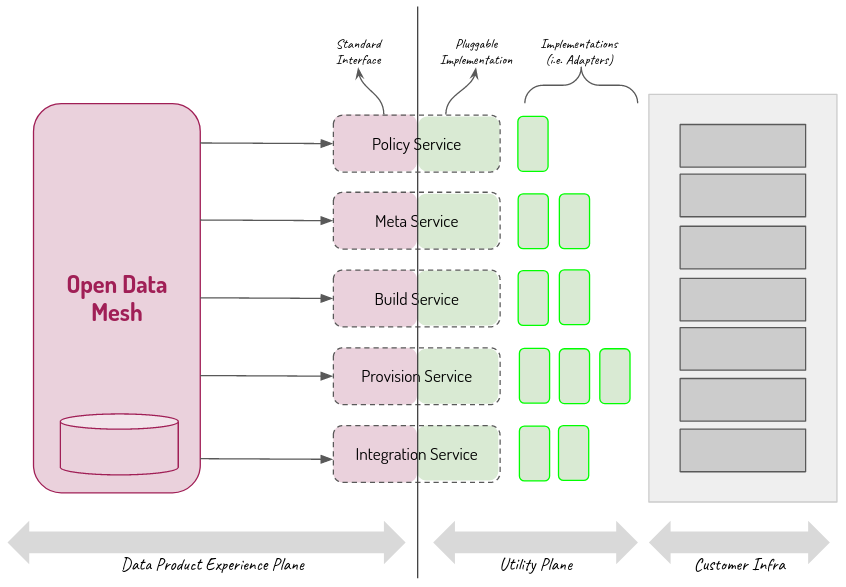
→ Self-Serve Data Platform
una piattaforma condivisa agnostica rispetto ai singoli domini che offre servizi in modalità self service per le funzionalità necessarie allo sviluppo dei data product evitando che se ne faccia carico ogni singolo dominio. Obiettivo è abbattere la complessità di utilizzo permettendo ai team di prodotto di concentrarsi maggiormente sulle logiche di integrazione e meno su aspetti tecnici.
→ Federated Computational Governance
garantire l’interoperabilità tra i dati esposti dai diversi data product per mezzo di un processo di governance federato in cui un team centrale, spesso composto dai rappresentati dei diversi team di prodotto e piattaforma, definisce delle policy globali che poi devono essere implementate localmente con il supporto della piattaforma e verificate in modo automatico.