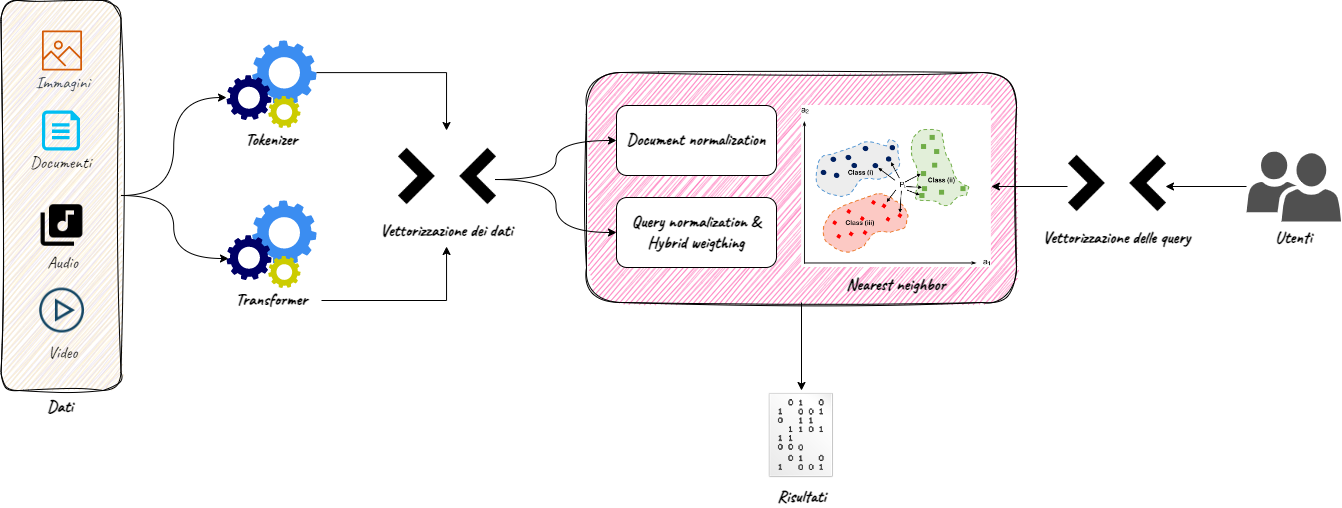
The daily use of search engines on business data (of customers, products, internal procedures…) is now widespread, both by business users and customers. Such widespread use of this technology has generated growing expectations on search has led to important advances, such as semantic search, that go beyond keyword search capabilities. However, both keyword and semantic search have important trade-offs to consider:
- Considering only keywords in a search may imply a loss of important parts of the context
- Considering only semantic search may imply a loss of important keywords
In addition, it is increasingly necessary to search or return information on unstructured data such as images or videos, especially when searching on ecommerce sites or in document research.
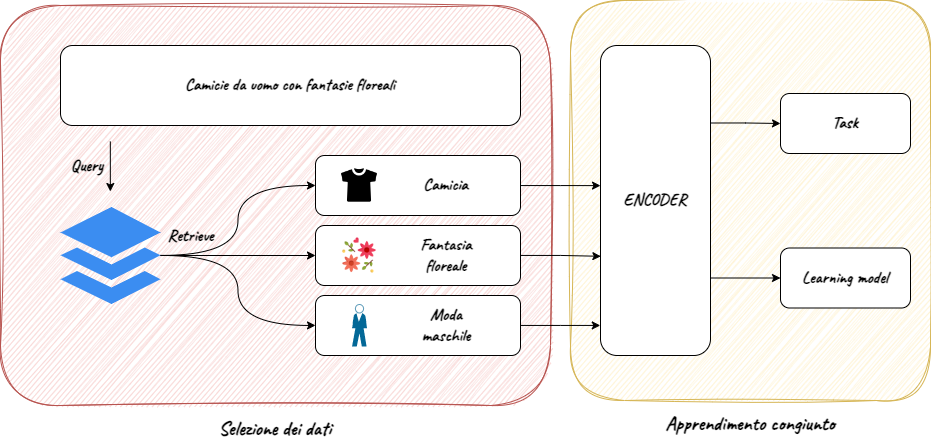
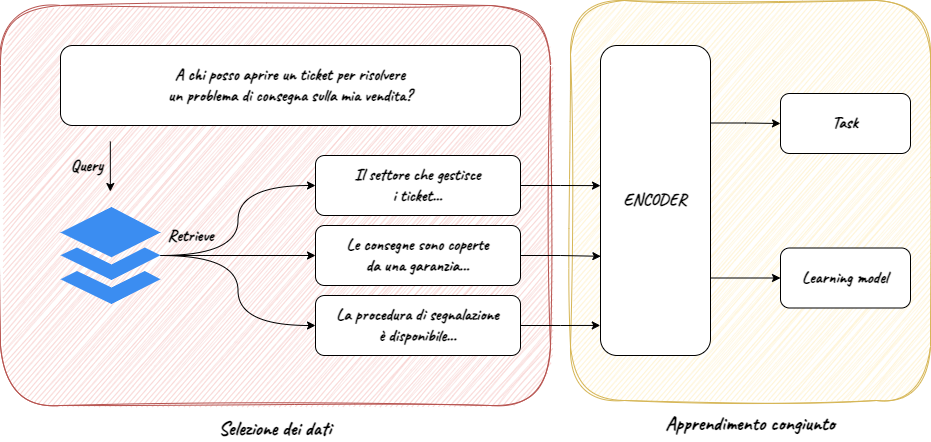
Multimodal Semantic Search represents a new approach to information search, specifically designed to simultaneously handle keywords, semantic context and scraping of structured and unstructured data, to provide a customised, timely and complete search experience.